Seems librarians are more interested in assessment today than was the case just a few years ago. There are many reasons for the quickening of interest but I suspect most cluster around one or the other of these themes:
- – a sense that libraries need to justify their existence, relevance, etc.
- – everybody’s talking about data so you need to have some to be seen as serious
In this sort of environment, the prudent course is to prepare for a dramatic rise in “Can we get some numbers on this?” questions. If you haven’t heard them yet they’re surely coming.
One way to get ready is to build in ways to measure new services as you develop them. Another is to look at data you already have and see if it can be enhanced to deliver a more compelling usage metric.
For my library, one option worth investigating–and the only place where I know I can capture every bit (and byte) of what’s happening with e-resources for off-campus users–is our EZproxy server. Is there a new way to look at the activity logs on that system? Let’s see…
Out of the box the activity log doesn’t offer much more than a way to track the level of use (large log file = busy server) and a source of forensic evidence to consult when an e-content vendor complains about excessive download activity. Yes, you can gather numbers that show how much each database is used but there are better sources for that information (e.g., COUNTER-compliant reports from vendors that cover all users, not just the off-campus cohort).
An idea
With one configuration tweak (by which I mean adding “Option LogUser” to the EZproxy config.txt file) you can begin capturing the login ID along with the standard EZproxy log data elements. This opens up some interesting possibilities.
Sensitive to privacy concerns, I’m not interested in what any one individual might be doing. But if I can aggregate activity from a group of users and link them back to a particular department, school or college–well, I can start to respond to hypothetical questions like this one:
What percentage of our total e-resource usage can we attribute to the faculty, staff and majors in the Economics department?
An answer might lead to a couple of different outcomes:
- – a sufficiently high number will tend to make an ally of the Economics department should the university begin to question funding levels for library resources.
- – a depressingly small number might serve to alert library staff to the fact that there’s work to be done by our e-resources collection builders and our library’s liaison to the Economics department
So, how do we get to that answer? Obviously we need a way to take the userID in this log file and figure out the academic affiliation. We’ll get there, but first, let’s get the proxy server’s log file into a form better suited to data analysis.
Here’s a sample line from our EZproxy server’s activity log. I’ve substituted xxxxxxx for the login ID:
68.100.94.96 – xxxxxxx [06/Sep/2013:15:21:37 -0500] “GET http://search.proquest.com:80/docview/894328918/fulltextPDF/1405A34DCF5752C0441/46 HTTP/1.1” 200 61895
If you’re familiar with web server logs, it’s pretty clear what’s being recorded. One line for each page, image, icon, whatever as it passes through the proxy server. Last week’s activity–our first week of classes–added 1.9+ million lines to the log file. Thinking about the scale of the data analysis challenge, I decided to convert the log file into a CSV (comma separated value) file that could then be imported into an SQL database. I’m most comfortable with MySQL but many other options exist.
How do you convert a text file of nearly 2 million lines into CSV format? Forget Excel (the 1,048,577th line will crash us). There are editors that can handle files of that size (joe comes to mind) but they’ll bog down swapping memory and scratch files as changes are made. You could use your favorite development language to write a utility to make the necessary changes but that’s a lot of work. Demonstrating the laziness that I’ve been told characterizes the better sysadmins, I went with a freely available unix tool that was built for just this sort of task.
Sed (stream editor) is a command line utility that edits files by running through the file’s stream of bits robotically executing editing changes on lines that match your instructions. Size of the file isn’t a concern (which makes it the perfect tool for this task).
Our goal is to render that the lines from our EZproxy log file into something that looks like this:
data element,next data element,another element,a final element
Our sample line begins like this:
68.100.94.96 – xxxxxxx
To remove the ‘-‘ between the IP address and the masked username, we use this command:
sed -i.bak 's/ - /,/g' ezp.log
to explain what’s happening: the -i.bak will create a backup before processing begins. That’s important if you’re not sure about what you’re asking sed to do.
the ‘s/ – /,/g’ section tells sed to substitute a comma (,) for the sequence [space][hyphen][space]. The “g” at the end means perform the substitution globally (for every occurrence it finds in the file).
now our sample line looks like this:
68.100.94.96,xxxxxxx [06/Sep/2013:15:21:37 -0500] “GET http://search.proquest.com:80/docview/894328918/fulltextPDF/1405A34DCF5752C0441/46 HTTP/1.1” 200 61895
We run another sed command, this time to change the [space][left bracket] sequence that follows the xxxxxxxx value into a comma.
sed -i.bak 's/ \[/,/g' ezp.log
The new wrinkle here? While we can tap the spacebar to put the space in our “find” text, we can’t just type a left bracket. We have to ‘escape’ that bracket so sed will see it as a bracket and not as part of the sed command syntax (which can also include brackets). That explains the “\” character just before the bracket. Now we have:
68.100.94.96,xxxxxxx,06/Sep/2013:15:21:37 -0500] “GET http://search.proquest.com:80/docview/894328918/fulltextPDF/1405A34DCF5752C0441/46 HTTP/1.1” 200 61895
Continuing, we change the [space]-0500] “GET[space] sequence to another comma. We don’t care about the GET, just the URL that follows it.
sed -i.bak 's/ -0500\] \"GET /,/g' ezp.log
Then another run, just in case there’s a POST lurking in the log:
sed -i.bak 's/ -0500\] \"POST /,/g' ezp.log
By now you may be wondering if you can combine multiple ‘sed’ edits in a single pass. Yes, there are several ways to handle that. I didn’t do that with this particular example because I needed to make sure each of my transformations was doing what I hoped (I’m no sed ninja).
The last step involves trimming that HTTP/1.1″ 200 61895 off the line (and every line in the file ends with a variation of those final digits (depending on the size of the item being proxied), we issue this command:
sed -i.bak -n 's/ HTTP.*$//p' ezp.log
And our sample line (as well as the rest of the lines in the file) now fit the CSV form (again, in the real output, that xxxxxxx is a username)
68.100.94.96,xxxxxxx,06/Sep/2013:15:21:37,http://search.proquest.com:80/docview/894328918/fulltextPDF/1405A34DCF5752C0441/46
Trivial now to import this into a table in a MySQL database. I set up 5 fields in my table. An auto-incrementing ID field and four data elements:

To pull the log data into this “proxy” table, issue this command at a mysql> prompt (be sure to change the path and to keep things simple, you’ll want to make sure the incoming csv file is readable by the mysql process. I’ll suggest you either “chmod 666” the input file or place it in your /tmp directory):
load data infile '/users/wallyg/ezp.log' into table proxy
fields terminated by ','
lines terminated by '\n'
(ip_address,username,use_date,source_url);
The final challenge
To link specific proxy activity with groups of users we need to know the academic affiliation each user. That information isn’t in our proxy server log. In my case, I found it in our university’s online directory. From the database that powers that system (based in the library for reasons that have more to do with the history of computing on campus than any one rational decision), I extracted two data elements for each user: the username and academic affiliation. I built another table in my database with these two fields (called it users) and imported the CSV data from the directory into the table.
I realize many readers won’t have easy access to a means of linking the loginID that appears in the EZproxy log with academic affiliation but you may find that your local ILS can supply the data or even your campus ERM group may be willing to help.
Once all the data elements are in place, it’s not difficult to build an SQL statement that says: “count all the transactions in this proxy server log file and cluster them by academic department with a subtotal for each department’s activity.”
While you could dump the result to the screen, I decided to send my results to yet another table (so I can start building a series of these result sets over time). I created a text file called stats.sql in my home directory and then piped it’s contents into Mysql. That step isn’t technically necessary but my first few attempts at getting the “join” right were taking a long time to process. Having the commands in an external file allowed me to put the job in the background.
As I got smarter about joins (and the value of a couple of indexes), I had the job running in 20-25 seconds. Here’s the SQL:

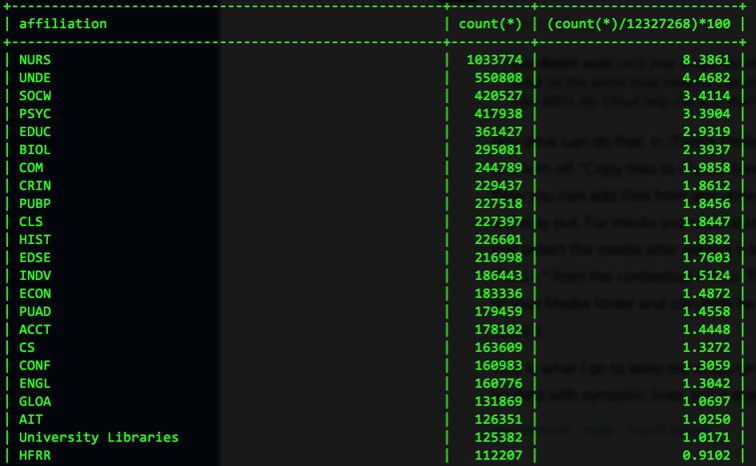
Turns out, 1,317,033 lines in the log file could be linked to particular users. [1]
Where the academic unit is a 4 letter abbreviation, that’s student majors in that department. Where it’s spelled out (e.g., English, University Libraries), that’s staff and faculty in those units. The difference is a serendipitous outcome of using two different sources for LoginID affiliation information (the student directory and a faculty/staff directory).
Not wanting to call anyone out, I’m only reporting here the units that approach or cross the 1% of activity threshold. And the Economics department? Well, they showed a very respectable 2%+ of all activity, placing them in the top 10 user category. Nursing majors are killing it but every unit can claim some percentage of the UNDE group (Undecided majors) so there’s something for everyone in these numbers…

I’ll run this process again in a few weeks. This data for this sample was the the first week of the Fall 2013 term–which I suspect means I may have a “serious student” bias among others in my results.
—
[1] If you’re wondering why that number isn’t closer to the 2 million lines I mentioned earlier, there’s a technical and somewhat boring explanation. Our campus-wide wireless activity goes through our proxy server so that NAT network will appear as a campus address to our e-vendors. During this period, there were 400,000+ lines in the file from wireless activity (we don’t require proxy server login for those users since they’ve already authenticated to get on the wireless network–hence EZproxy neither sees nor records a LoginID).
October 1 update…
As the month ended, I ran the usage by affiliation query again–on the 12 million lines in September’s log file. Nursing is still our #1 user although a few of the other groups moved up or down a few notches: