
Spent some time with Dartmouth University’s Summon™ installation the other day. Thanks to Dartmouth for making it available on the open web. And while I’m at it, I should also thank George Mason (seems we overlap on subscriptions so I was able to access the content that the Summon™ service uncovered).
What is the Summon™ service?
Before tackling that, it’s worth spending a minute or two thinking about how one goes about searching content that’s distributed across the web.
If you’ve ever looked into digital storage solutions, you’ve probably heard that you can achieve any two of these three attributes: speed, reliability or economy. Build a system that’s fast and reliable and it won’t be inexpensive. Develop a reliable but inexpensive solution and you’ll sacrifice performance. A RAID 0 stripe is fast and cheap but if one drive dies, you lose everything (ixnay reliablilty). You get the general idea.
Web-based searching’s not all that different, you have to balance a set of sometimes conflicting attributes.
There are two approaches:
- Just-In-Case. Google is the quintessential example. Before the user makes a query, the search system has collected, normalized and indexed the desired content. Your search runs against this single index. It’s fast but you are sacrificing currency (reliability) of information. You can retrieve an item only if it was collected and indexed prior to your query. If it just appeared on the web, it’s invisible to you.
- Just-In-Time. Federated searching follows this model. Make a query and the search engine sends out simultaneous real-time requests to other hosts, bringing back content and presenting it. You’re giving up speed to improve reliability (currency) of information.
The Summon™ service follows the just-in-case model. As ProQuest describes it, Summon™ offers “…a Google-like search experience, allowing researchers to use one search box to discover credible and reliable library content.” ProQuest is leveraging the content it controls (e.g., Chadwyck-Healy, Cambridge Scientific Abstracts, ProQuest, UMI Dissertations, article-level metadata from SerialsSolutions, etc.) as well as content contributed by some of its competitors to build a single, unified index that sits behind that “single search box.”
Competitors? Well, yes. ProQuest pitches Summon™ to competing content providers as a way to boost renewal rates and usage, promising to drive customers their way with outbound links once they’ve given ProQuest indexing access to their full-text content. As they make quite clear to potential partners, “Your full text content will never be displayed in the Summonâ„¢ service.”
Obviously, this academic-web-in-a-single-searchbox approach offers a number of advantages and it’s not at all hard to see why many public services librarians find it compelling:
- There’s not so much to explain (who doesn’t get how Google works?)
- The library has access to all of the content in the system, minimizing user frustration
- It is fast, faceted and looks great
- Don’t use Google™ for your research, use our ‘library google’ instead.
But, tradeoffs have been made and they deserve our attention as well.
- The library moves from an open gateway model to something more closely resembling a walled garden
- Users will miss what ProQuest hasn’t included in the database
- Retrieval likely skews toward sources that provide Summon™ with full-content not just metadata
- By design, the Summon™ service can never be absolutely current
- Hard to know exactly what has and hasn’t been searched. Does content come and go from the Summon™ database based on publisher/ProQuest agreements? Is that documented? Regularly reported?
- Summon’s owner ProQuest is in the business of selling content. Do we just trust that ProQuest won’t bump it’s holdings up higher in the retrieval sets (to encourage libraries to renew those subscriptions)?
A service like Summon™ is clearly a useful tool and ProQuest is to be commended for undertaking such an ambitious project. For a variety of reasons, few would attempt to apply just-in-case indexing to the full-range of library content. However, as ProQuest already controls much of the content in a given library’s subscription list leveraging this to strengthen their hold on the library market makes business sense. Similar, in its way, to what OCLC is trying to do by extending WorldCat to encompass “web-scale management services.” The fact that both corporations favor the neologism “web-scale” is probably just a coincidence (could both have hired the same library marketing research firm?).
Enthusiasm for the Summon™ service will vary depending on your sense of the problem to be solved:
- If you worry most about the helping the user who asks, “find me something useful” then Summon™ is a winner.
- If your job depends on satisfying the user who asks, “find me everything” or “is this absolutely current?” then Summon™ is just a distraction.
At some level, it seems the utility and value of something like Summon™ is inversely proportional to the sophistication and information needs of the user.
# #
One final question occurred to me as I was testing the currency of the Summon™ database at Dartmouth. Are there potential problems moving from the indexed data that Summon™ uses for retrieval and the link-out that occurs when it’s time to move from the index to the actual content?
I ran a search for iPad:
![]()
Retrieved 6,600 hits (very encouraging). Selected one at random off the first page of results:
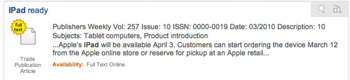
I clicked the “Full Text” link and got this (no mention of iPad anywhere on the page):

Now that’s just 1 out of 6,600 hits so statistically it’s insignificant…but it did happen and on the first page of results. The question is whether this exposes a weakness in the “search it over here…then retrieve it from over there” model or was it just a transient blip?
As an example of the risk we run as we chase diversity from the library search business, consider this: I ran the same “ipad’ search on the University of Calgary Libraries Summonâ„¢ beta and found the exact same erroneous “HBO Series ‘The Pacific’ Spawns Books Rush” result on page one of the results.
At least a SaaS product is consistent.