
Earlier today I was running a few SQL queries against our local Voyager system–preparing for the upcoming metadata migration to a consortial implementation of Alma. My tool of choice for this sort of thing is Navicat and as I worked through a series of “count this for me” queries, like…
- how many bib records have NULL in the NETWORK_NUMBER field? 54,995
- how many have an OCLC number in that field? 1,640,304
- exactly how many bib records are there in the database? 3,490,929
…I realized that Navicat made the export of data in a variety of formats a reasonably trivial exercise. Thinking it might be somehow useful for people sharpening their text-mining chops in our new Digital Scholarship Center (2nd floor, Fenwick Library), I decided to build a text file of brief bibliographic data (author, title, publisher, date, etc.) from the 3+ million records in our Voyager database. A simple click in a checkbox produced both JSON and XML versions of the metadata
The zipped versions of these files are roughly 200MB each.
Click the link below to retrieve the JSON recordset.
https://dl.dropboxusercontent.com/u/166896/MasonCatalog.json.zip
XML? Click below…
https://dl.dropboxusercontent.com/u/166896/MasonCatalog.xml.zip

Sample record in the JSON version of the file
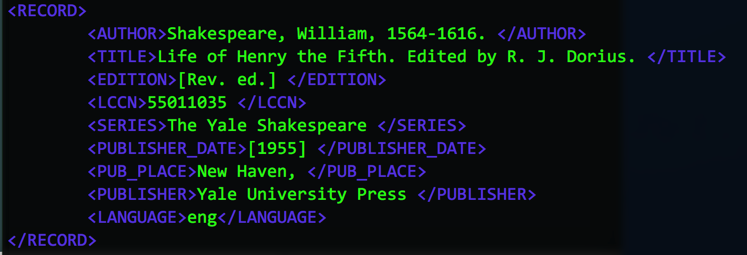
The XML version has a couple more data fields (LCCN and SERIES) if available in a record.
If you end up using this data for anything useful (or need a slightly different extract), send me a tweet